もともとPythonには辞書型(dictionary)といって、項目別にデータを記録できる形式があります。
これを表でも使えるようにしたのがPandasです。
まず単純な表でやってみましょう。
以下のような名前、年齢、性別、身長、体重の表を用意します。
日本語入力は処理が増えるので、ここでは英語項目にします。
「sample_data.csv」という名前を付けます。
↓「sample_data.csv」の内容
| name | age | sex | height | weight |
|---|---|---|---|---|
| A | 25 | male | 181 | 81 |
| B | 40 | female | 158 | 61 |
| C | 32 | male | 165 | 67 |
| D | 37 | female | 171 | 61 |
| E | 56 | male | 175 | 89 |
| F | 49 | female | 161 | 61 |
| G | 65 | male | 168 | 72 |
| H | 72 | female | 155 | 57 |
| I | 58 | female | 148 | 52 |
| J | 41 | male | 176 | 85 |
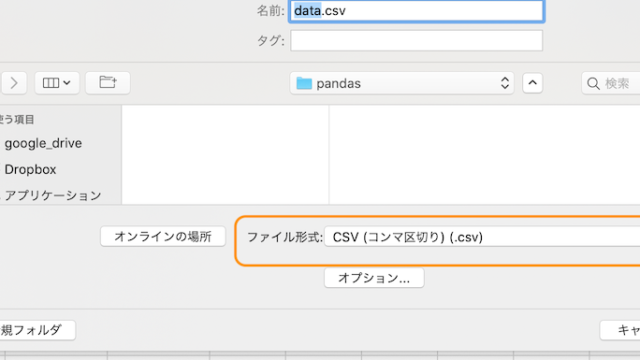
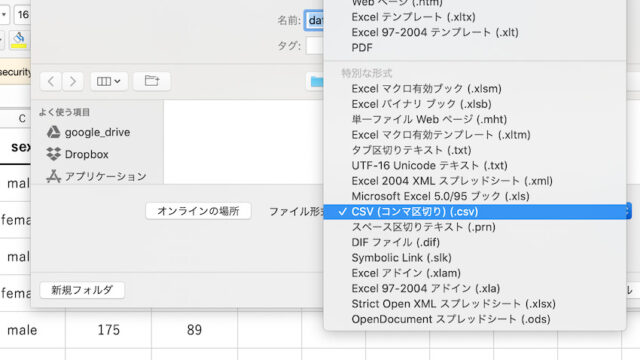
このファイルをエクセルから、「csv形式」で保存します。
エクセルの「名前を付けて保存」 → 「形式」 →「csv(カンマ区切り)」でできます。
import pandas as pd
#pandasをpdという略称で使っていきます。
df = pd.read_csv('sample_data.csv', index_col='name')
#pandasの「read_csv」という関数でデータファイルをdfに読み込みます。
#同時に名前(name)の欄をインデックスに指定します。
print(df)
#読み込んだデータを表示します。
データフレームという形式です。
print(type(df))
#dfの型(形式)を打ち出します。
class ‘pandas.core.frame.DataFrame’
pandasのデータフレーム形式となっています。
データのグラフを書く(別ページ)
データからパラメータを計算する
などなど、色々できるんだよ。
まず、pandasにはこのデータの特徴を一覧できる機能があります。
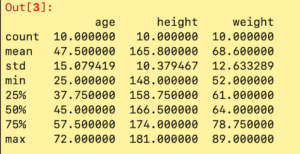
df.describe()とすると、データの色々な統計パラメータが出力されます。
count:サンプル数、mean:平均、std:標準偏差、min:最小値、25,50,75%: パーセンタイル、max:最大値
df.info()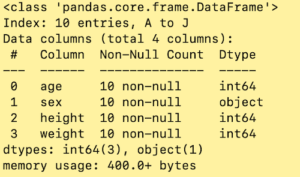
とすると、データに入っているそれぞれの値の特徴が見れます。
int64というのは整数値が入っているということです。age, height, weightの値ですね。
objectというのはここでは文字列が入っています。sexのmale, femaleに対応しています。
ここでBMIを計算してみます。
BMI = 体重(kg) / (身長(m)の二乗)
ですので
df['BMI'] = df['weight'] / ((df['height'] / 100) ** 2)
#体重割る身長の2乗を計算して、'BMI'という項目に入れるのように記載することができます。
df[項目名]でデータフレーム内の列を抜き出しています。
**は2乗の計算です。
ここで
print(df)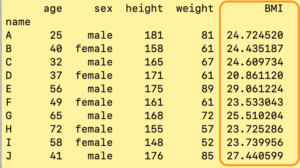
と、dfのBMIの項目が加わっているのがわかります。
こうやって手を加えたデータフレームをcsvで保存するのは簡単です。
df.to_csv('sample_data_bmi.csv')
#dfの内容を「sample_data_bmi.csv」という名前で保存フォルダを見ると、sample_data_bmi.csvというファイルがあり
| name | age | sex | height | weight | BMI |
|---|---|---|---|---|---|
| A | 25 | male | 181 | 81 | 24.724520008546747 |
| B | 40 | female | 158 | 61 | 24.435186668803073 |
| C | 32 | male | 165 | 67 | 24.609733700642796 |
| D | 37 | female | 171 | 61 | 20.86111966075032 |
| E | 56 | male | 175 | 89 | 29.06122448979592 |
| F | 49 | female | 161 | 61 | 23.533042706685695 |
| G | 65 | male | 168 | 72 | 25.510204081632658 |
| H | 72 | female | 155 | 57 | 23.725286160249738 |
| I | 58 | female | 148 | 52 | 23.739956172388606 |
| J | 41 | male | 176 | 85 | 27.44059917355372 |
BMIという項目が追加されています。
対話をするように書けるのが便利です。
これは、データフレームを一つのオブジェクト(モノ)として考えるという概念で作っているためです。 Pythonは「オブジェクト指向」のプログラミング言語と言われており、同じように対話感覚で使えるツールが数多くそろっているので便利なのです。

データのかたまりがモノとして操作できるような感じですかね。