こんにちは。整形外科医のDr.レオです。
私は臨床現場での手術計画や画像解析でプログラミングをフル活用しています。
画像処理にはいろいろなソフトウェアがあり、テキストファイル形式でデータを書き出すことがよくあります。
データを1個ずつコピーペーストしていたら何千、何万というデータには対応できません。
そのため、
「テキストファイルから自分の欲しいデータを取り出す」
プログラムを書ければ圧倒的に効率が上がります。
Pythonは
ファイルの読み取りが簡単
なので、こういった作業にとても適しています。
ここではCT表面画像のデータファイルの読み込みを例を用いて説明します。
1例なのでいろいろなテキストファイルに応用可能です。
1.出力されたテキストファイルを見て作戦をたてる
CT画像から骨の表面画像を作成し、骨のある点をポイントして位置座標を取りたいとします。
骨の位置座標をとる時、MeshLabというソフトウェアで行うととても便利です。
このMeshLabから出されるデータは.ppというファイルに入っています。
例えば、CTデータを表面画像化して、点データをとった時の例を示します。
手首の骨のデータ上にとった3点を
test.ppで書き出したとします。
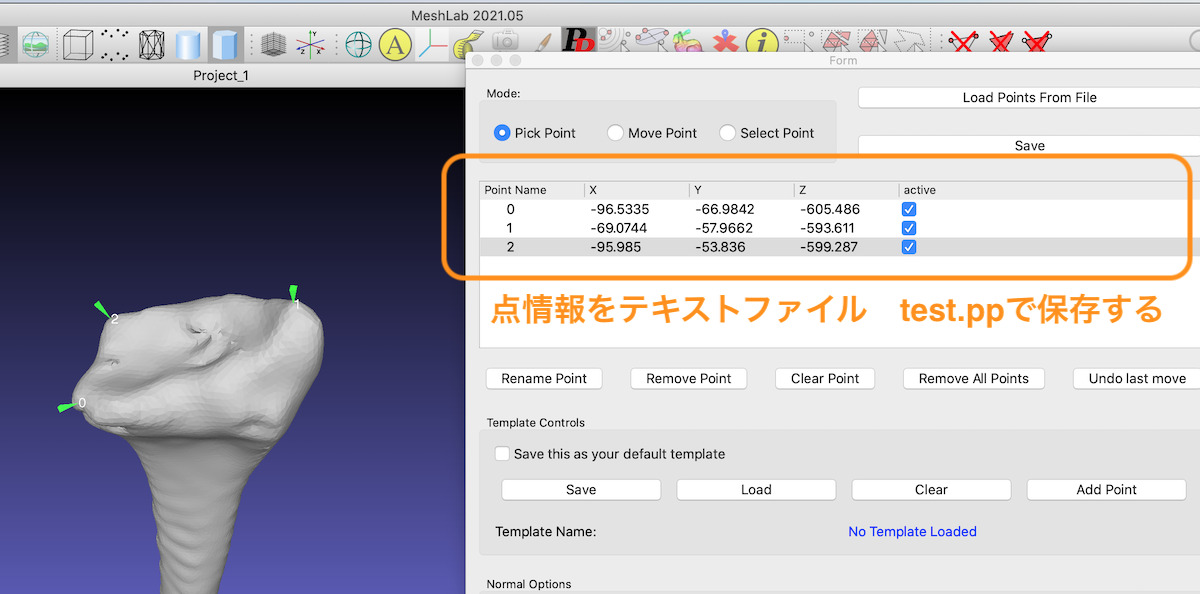
この書き出したデータをテキストファイルで開くと
<!DOCTYPE PickedPoints>
<PickedPoints>
<DocumentData>
<DateTime date=”2021-09-16″ time=”16:33:23″/>
<User name=”programming”/>
<DataFileName name=”test.stl”/>
<templateName name=””/>
</DocumentData>
<point x=”-96.533485″ y=”-66.984184″ z=”-605.48572″ active=”1″ name=”0″/>
<point x=”-69.074371″ y=”-57.966228″ z=”-593.61072″ active=”1″ name=”1″/>
<point x=”-95.984985″ y=”-53.836006″ z=”-599.28717″ active=”1″ name=”2″/>
</PickedPoints>
というような中身になっています。
このファイルから各点のx, y, zの座標を抜き出したいと考えます。
テキストの中身を見て作戦をたてます。
いろいろな考え方があると思います。
ファイルを開く
↓
1行ずつ読み取る
↓
‘<‘と’/>’の間を抜き出す
↓
スペースで分ける
↓
“point”が最初の項目にあるかで点を書いているかどうかを判断する
↓
“point”があればx=, y=, z=の項目を抜き出す。(なければスルー)
x, y, zは「”」でsplitして間を抜き出してfloat(数値)型にする
↓
[x, y, z]座標をpoint_listというリストに入れていく
↓
point_listを返す
でいけそうです。
2.作戦を参考にコードをかく
作戦を立てたらこれを実行すべくコードを書きます。
import numpy as np
#座標はnumpyのarray型で出すのでnumpyをインポート
point_list = []
#point_listという空のリストを作成
with open('test.pp') as f:
#「test.pp」を開く
line = f.readline()
# lineという変数にファイルの最初の1行を読む
while line:
# lineが空になるまでインデント以下の処理を繰り返す
inside_line = line[line.find('<') + 1: line.find('/>')]
# inside_lineにlineの内'<'と'/>'の間の文字列を入れる
words = inside_line.split(' ')
# inside_lineをスペース' 'で分け、単語をwordsに入れる
if words[0] == 'point':
# 単語の最初が'point'であれば以下の処理を実行
for word in words:
# スペースでわけた単語ごとに実行
if 'x=' in word:
# 'x='が単語の中にあれば以下を実行
x = float(word.split('"')[1])
# 単語を「"」でわけ、間の文字列を数字にしてxに入れる
elif 'y=' in word:
# 以下y,zはxと同様処理
y = float(word.split('"')[1])
elif 'z=' in word:
z = float(word.split('"')[1])
point_list.append(np.array([x, y, z]))
# [x, y, z]は座標なのでnumpyのarray型にしてpoint_listに追加
line = f.readline()
#次の行を読み込み、whileループに戻る
print(point_list)
#最終的なpoint_listを出力
[array([ -96.533485, -66.984184, -605.48572 ]),
array([ -69.074371, -57.966228, -593.61072 ]),
array([ -95.984985, -53.836006, -599.28717 ])]
無事に出力できました。
一つの出力できたからといって安心せず、
複数のデータで正しく検討することが大事です。
3.関数として外から使う
スクリプトを毎回書いていると大変なので、
ここで、これを関数として定義することもできます。
read_point.pyファイルを作成し、中身に関数を記載します。
ファイル名だけ自由に変えられるよう、
file_name
という変数にしておきます。
import numpy as np
def read_pp(file_name):
point_list = []
with open(file_name) as f:
line = f.readline()
while line:
inside_line = line[line.find('<') + 1: line.find('/>')]
words = inside_line.split(' ')
if words[0] == 'point':
for word in words:
if 'x=' in word:
x = float(word.split('"')[1])
elif 'y=' in word:
y = float(word.split('"')[1])
elif 'z=' in word:
z = float(word.split('"')[1])
point_list.append(np.array([x, y, z]))
line = f.readline()
return point_list
として
外部で以下のように入力してみます。
import read_point
point_list = read_point.read_pp('test.pp')
print(point_list)
[array([ -96.533485, -66.984184, -605.48572 ]),
array([ -69.074371, -57.966228, -593.61072 ]),
array([ -95.984985, -53.836006, -599.28717 ])]
無事データが取り出せました。
4.クラスにして外から使う
私自身はよく使うソフトウェアの出力ファイルはクラスにしています。
ここでは
「point_class.py」
と名前をつけて以下のようなスクリプトを作ります。
中でMeshlabPpとしてクラスを定義します。
import numpy as np
"""Meshlabでの.ppファイルデータのクラスMeshlabPpを定義"""
class MeshlabPp(object):
def __init__(self, file_name):
self.point_list = read_pp(file_name)
#クラス内で先程の関数を呼び出して座標を読み込めるようにしている
"""ここから先程の関数"""
def read_pp(file_name):
point_list = []
with open(file_name) as f:
line = f.readline()
while line:
inside_line = line[line.find('<') + 1: line.find('/>')]
words = inside_line.split(' ')
if words[0] == 'point':
for word in words:
if 'x=' in word:
x = float(word.split('"')[1])
elif 'y=' in word:
y = float(word.split('"')[1])
elif 'z=' in word:
z = float(word.split('"')[1])
point_list.append(np.array([x, y, z]))
line = f.readline()
return point_list外部から呼び出して使用します。
import point_class
test_pp = point_class.MeshlabPp('test.pp')
# MeshlabPpクラスとして「test.pp」ファイルを読み込んだtest_ppを作ります。
print(test_pp.point_list)
# test_pp.point_listを出力[array([ -96.533485, -66.984184, -605.48572 ]),
array([ -69.074371, -57.966228, -593.61072 ]),
array([ -95.984985, -53.836006, -599.28717 ])]
出力できました。
こうしておくと、
使用したソフトウェアが違っても
それぞれのソフトウェアにあった作業で点座標などをオブジェクトに読み込む
↓
point_listという共通の属性名で点座標を出力できる
と、データの扱いを共通させることができます。

半日かかって座標を取り出すプログラムが書けました〜

プログラミングあるあるだな
プログラミングをしていると、
「手作業で入力した方が、長時間かけてプログラミングするより効率がよかった」
などと皮肉を言われることもあります。
それでも、単純作業に比べて
プログラミングはやればやるほど経験値になる
ので、大事な経験だと私は思っています。