

法則にしたがってテキストから情報を読み出すのは簡単にできるよ。
こんにちは。整形外科医レオです。
Pythonの強みとして
「ファイルの読み書きがしやすい」
という点があります。
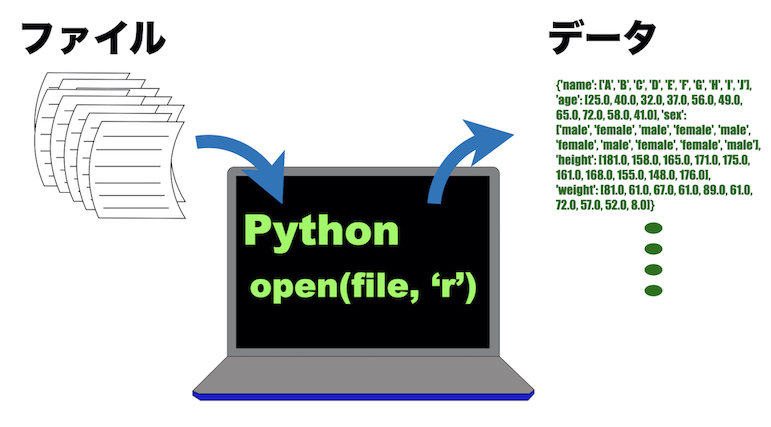
ここでは、Pythonを使ってテキストファイルから欲しい情報を抜き出すことを行います。
例として、エクセルの表からそれぞれのデータを取り出す方法を書きたいと思います。
以下のような表を題材にします。
| name | age | sex | height | weight |
|---|---|---|---|---|
| A | 25 | male | 181 | 81 |
| B | 40 | female | 158 | 61 |
| C | 32 | male | 165 | 67 |
| D | 37 | female | 171 | 61 |
| E | 56 | male | 175 | 89 |
| F | 49 | female | 161 | 61 |
| G | 65 | male | 168 | 72 |
| H | 72 | female | 155 | 57 |
| I | 58 | female | 148 | 52 |
| J | 41 | male | 176 | 85 |
これを
sample_data.csv
という名前でcsv形式で保存します。
csv形式はカンマ区切り形式といいます。
ファイルはエクセルで開くと表になりますが、テキストファイルで開くと項目がカンマで区切られているのがわかります。
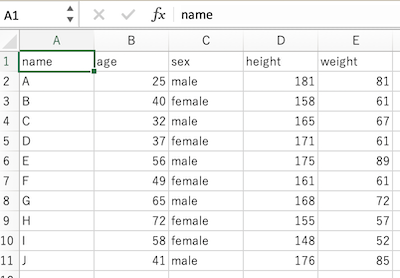
エクセルでsample_data.csvを開いたもの

テキストエディタでsample_data.csvを開いたもの
ここからはこのcsvファイルを開いて、中のデータを抽出する方法を説明します。
実はこのような整ったデータであれば、pythonのpandasというツールを使用すれば簡単に抽出できます。
import pandas as pd
df = pd.read_csv('sample_data.csv')しかし、ソフトウェアのテキストやホームページからファイルやスクリプトファイル
など、様々なテキストファイルからデータを抽出するときに、これらの流れを知っているといろいろな分野に応用できます。
そのため、ここではあくまでテキストファイルかデータを読み取る例として、pandasなどツールは使わずに行います。
ファイルを開く
pythonのなかでは
open(‘ファイル名’, ‘モード’)
でファイルを開きます。
モードは読み取り、書き込み、読み書きがありますが、
読み取りは’r’です。
f = open('sample_data.csv', 'r')
#開いたファイルデータをfという変数に入れ、操作できるようにする
#処理を行うプログラム
#
#
#
f.close()
#ファイルを閉じる
処理が終わったら
f.close()
で閉じています。
さて、ここからファイルを読み取っていきます。
readline()で1行ずつファイルを読み取る
readline()
という方法を使うと1行ずつ書き出していきます。
f.readline() #1行書き出す
#'name,age,sex,height,weight\n'
f.readline()
#'A,25,male,181,81\n'
f.readline()
#'B,40,female,158,61\n'
・
・
f.readline()
# 'J,41,male,176,85'
f.readline()
# ''
f.readline()
# ''
f.close()
# いったんファイルを閉じます1行ずつファイルを読んでいきます。
最後にたどり着くと、ずっと空の行”をはき出します。
各値はカンマで区切られています。
ここで最後の 「\n」は改行を示します。
このreadline()を利用して、
年齢、性別などパラメータ別に分けます。
f = open('sample_data.csv', 'r')
header = f.readline()
#1行目をheaderという変数に入れる
header
#'name,age,sex,height,weight\n'確認のためheaderと入力しています。ここでprint関数を使うと改行として表示されるので「\n」の存在がわからなくなるため注意が必要です。
print(header)
#name,age,sex,height,weight
#
header[:-1]
#'name,age,sex,height,weight'[:-1]として最後の1文字を抜かすと改行記号が省けます。
parameters = header[:-1].split(',')
#改行以外をコンマで分けて、parametersという変数に入れる
print(parameters)
#['name', 'age', 'sex', 'height', 'weight']
sample_dic = {}
#空の辞書を用意する
for parameter in parameters:
sample_dic[parameter] = []
#パラメータごとにからのリストとする。
line = f.readline()
#データの最初の1行読む
while line:
#以下の処置をlineが空になるまで続ける。空になったら終了。
words = line[:-1].split(',')
#wordsにlineの改行以外をコンマでわけてリストにして入れる。
#データの1行目なら['A', '25', 'male', '181', '81']
for i in range(len(parameters)):
#wordsの長さだけ操作を行う。
sample_dic[parameters[i]].append(words[i])
#wordsのi+1番目を辞書の中の一致する位置のパラメータのリストに入れる
line = f.readline()
#新たな行を読み込む
f.close()
print(sample_dic)
{
‘name’: [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘I’, ‘J’],
‘age’: [’25’, ’40’, ’32’, ’37’, ’56’, ’49’, ’65’, ’72’, ’58’, ’41’],
‘sex’: [‘male’, ‘female’, ‘male’, ‘female’, ‘male’, ‘female’, ‘male’, ‘female’, ‘female’, ‘male’],
‘height’: [‘181’, ‘158’, ‘165’, ‘171’, ‘175’, ‘161’, ‘168’, ‘155’, ‘148’, ‘176’],
‘weight’: [’81’, ’61’, ’67’, ’61’, ’89’, ’61’, ’72’, ’57’, ’52’, ‘8’]
}
これで
sample_dic[パラメータ]
で各パラメータが取り出せます。

数字を数字で入れたいのであれば
文字列を数字に変換してみましょう。
ここではtry, exceptを用います。
例えば
words = ['1', '2.3','a','4.5']
#wordsに数字と文字をごちゃまぜにして入れます。
output = []
for word in words:
output.append(float(word))
print(output)
とすると
[1.0]
[1.0, 2.3]
—————————————————————————
ValueError Traceback (most recent call last)
in
2 output = []
3 for word in words:
—-> 4 output.append(float(word))
5 print(output)
6
ValueError: could not convert string to float: ‘a’
‘a’という文字列になったとき小数点のfloat型に変換できずに止まってしまいます。
ここで
words = ['1', '2.3','a','4.5']
output = []
for word in words:
try:
output.append(float(word))
except:
output.append(word)
print(output)[1.0]
[1.0, 2.3]
[1.0, 2.3, ‘a’]
[1.0, 2.3, ‘a’, 4.5]
とtryで実行しようとしてエラーになると諦めてexceptに飛んでくれます。
最後まで処理ができます。
これをデータの入力に応用します。
while line:
words = line[:-1].split(',')
for i in range(len(parameters)):
try:
value = float(words[i])
except:
value = words[i]
sample_dic[parameters[i]].append(value)
line = f.readline()
f.close()
print(sample_dic){
‘name’: [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘I’, ‘J’],
‘age’: [25.0, 40.0, 32.0, 37.0, 56.0, 49.0, 65.0, 72.0, 58.0, 41.0],
‘sex’: [‘male’, ‘female’, ‘male’, ‘female’, ‘male’, ‘female’, ‘male’, ‘female’, ‘female’, ‘male’],
‘height’: [181.0, 158.0, 165.0, 171.0, 175.0, 161.0, 168.0, 155.0, 148.0, 176.0],
‘weight’: [81.0, 61.0, 67.0, 61.0, 89.0, 61.0, 72.0, 57.0, 52.0, 8.0]
}
readlines()で一気にファイルを読み取る
readline()では1行ごとでしたが
readlines()という方法だと一気に全部の行をリストにして読み出します。
f = open('sample_data.csv', 'r')
words = f.readlines()
print(words)[‘name,age,sex,height,weight\n’,
‘A,25,male,181,81\n’,
‘B,40,female,158,61\n’,
‘C,32,male,165,67\n’,
‘D,37,female,171,61\n’,
‘E,56,male,175,89\n’,
‘F,49,female,161,61\n’,
‘G,65,male,168,72\n’,
‘H,72,female,155,57\n’,
‘I,58,female,148,52\n’,
‘J,41,male,176,85’]
wordsには1行ずつのデータが入っています。
これらはカンマで区切られています。
ここでも最後の 「\n」は改行を示します。
wordsはリストなので
例えばwords[0]には1行目、words[3]には4行目が入っています。
words[0]
# 'name,age,sex,height,weight\n'
words[3]
# 'C,32,male,165,67\n'
改行記号はいらないので、最後の1文字を外すようにします。
words[0][:-1]
# 'name,age,sex,height,weight'
カンマで区切られているのでカンマで分けると項目ごとのリストになります。
parameters = words[0][:-1].split(',')
print(parameters)
# ['name', 'age', 'sex', 'height', 'weight']
さて、ここで辞書を定義します
sample_dic = {}
項目別に入れていきます。
#パラメータごとの空のリストを辞書内に作成
for parameter in parameters:
sample_dic[parameter] = []
for i in range(len(words) - 1):
#行の長さ分、繰り返して実行
for j in range(len(parameters)):
#パラメータごとに繰り返して実行
sample_dic[parameters[j]].append(words[i + 1][:-1].split(',')[j])
#対象パラメータごとに一致する部分のデータを加える。
print(sample_dic)
{‘name’: [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘I’, ‘J’],
‘age’: [’25’, ’40’, ’32’, ’37’, ’56’, ’49’, ’65’, ’72’, ’58’, ’41’],
‘sex’: [‘male’, ‘female’, ‘male’, ‘female’, ‘male’, ‘female’, ‘male’, ‘female’, ‘female’, ‘male’],
‘height’: [‘181’, ‘158’, ‘165’, ‘171’, ‘175’, ‘161’, ‘168’, ‘155’, ‘148’, ‘176’],
‘weight’: [’81’, ’61’, ’67’, ’61’, ’89’, ’61’, ’72’, ’57’, ’52’, ‘8’]}
となり、各パラメータが抜き出せます。




同様に数値と文字のデータを分けたければ、この部分は
for i in range(len(words) - 1):
for j in range(len(parameters)):
try:
value = float(words[i + 1][:-1].split(',')[j])
except:
value = (words[i + 1][:-1].split(',')[j])
sample_dic[parameters[j]].append(value)
print(sample_dic){
‘name’: [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘I’, ‘J’],
‘age’: [25.0, 40.0, 32.0, 37.0, 56.0, 49.0, 65.0, 72.0, 58.0, 41.0],
‘sex’: [‘male’, ‘female’, ‘male’, ‘female’, ‘male’, ‘female’, ‘male’, ‘female’, ‘female’, ‘male’],
‘height’: [181.0, 158.0, 165.0, 171.0, 175.0, 161.0, 168.0, 155.0, 148.0, 176.0],
‘weight’: [81.0, 61.0, 67.0, 61.0, 89.0, 61.0, 72.0, 57.0, 52.0, 8.0]
}
となります。
まとめ
ここでのコードのまとめです。
f = open('sample_data.csv', 'r')
header = f.readline()
sample_dic = {}
for parameter in parameters:
sample_dic[parameter] = []
line = f.readline()
while line:
words = line[:-1].split(',')
#データの1行目なら['A', '25', 'male', '181', '81']
for i in range(len(parameters)):
try:
value = float(words[i])
except:
value = words[i]
sample_dic[parameters[i]].append(value)
line = f.readline()
f.close()
print(sample_dic)
f = open('sample_data.csv', 'r')
words = f.readlines()
parameters = words[0][:-1].split(',')
sample_dic = {}
for parameter in parameters:
sample_dic[parameter] = []
for i in range(len(words) - 1):
for j in range(len(parameters)):
try:
value = float(words[i + 1][:-1].split(',')[j])
except:
value = (words[i + 1][:-1].split(',')[j])
sample_dic[parameters[j]].append(value)
print(sample_dic)
上で述べたようにpandasのread_csvを使うと
import pandas as pd
df = pd.read_csv('sample_data.csv')
print(df)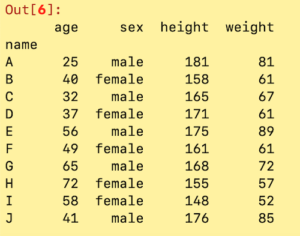
pandasって便利ですね。