

このページでは
「プログラミングでグラフを書く」
というイメージをつかむため、簡単な表を用いて実例を示します。
- Pythonでグラフを書く簡単な具体例
- Pythonのseabornでグラフを書く
- Pythonのmatplotlibでグラフを書く
- 2つの相違点について
- seabornはデータを表で取り込んでグラフを書く
- matplotlibはデータの数列を入力してグラフを書く
- データを持っていて可視化するのはseabornの方が手軽
「Pythonでグラフを書く」といってもやまほど方法があります。
その中でもっともメジャーなツールが
- matplotlib
- seaborn
の2つです。
実はseabornのバックグラウンドではmatplotlibが動いているので、これらは共通と言えます。
seabornではより
表データをグラフにする
ことに特化し、様々なツールが用意されています。
ここでは簡単な表を用いて
「Pythonでグラフを書く」
ということを2つのツールmatplotlibとseabornを用いて実践してみます。
具体例によるグラフの描画
例として、簡単な表を用います。
①データと読み込み
10人分の名前、年齢、性別、体重、身長を作ります。
日本語入力すると、読み取りと書き出しにひと手間かかるため、項目は英語にします。
エクセルで開いて、「.csv」という形式で保存しておきます。
ここでは”sample_data.csv”というファイルで保存します。
| name | age | sex | height | weight |
|---|---|---|---|---|
| A | 25 | male | 181 | 81 |
| B | 40 | female | 158 | 61 |
| C | 32 | male | 165 | 67 |
| D | 37 | female | 171 | 61 |
| E | 56 | male | 175 | 89 |
| F | 49 | female | 161 | 61 |
| G | 65 | male | 168 | 72 |
| H | 72 | female | 155 | 57 |
| I | 58 | female | 148 | 52 |
| J | 41 | male | 176 | 85 |
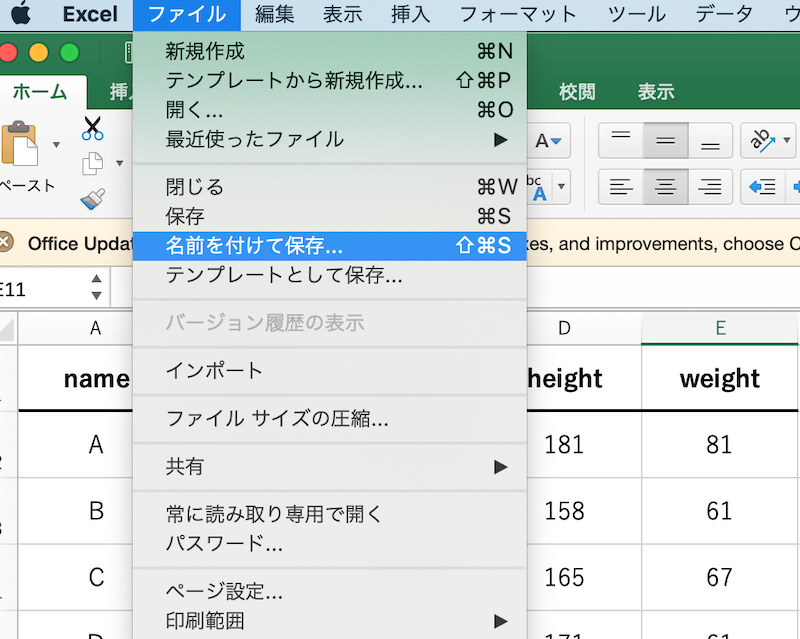
エクセルでは、このような表をcsvで保存しようとするときは、
「名前を付けて保存」→「ファイル形式」→「csv(コンマ区切り形式)」
となります。
csv形式は広く使われており、ほとんどの表を扱うソフトで扱えます。
②プログラムを動かす準備
MacのターミナルやWindowのコマンドプロンプトからiPythonと入力し、Pythonを動かします。

ipythonが動き出したら、コマンドを入力します。
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
#matplotlibをplt, pandasをpd, seabornをsnsという略称で使います。
df = pd.read_csv('sample_data.csv', index_col='name')
#サンプルデータを読み込み、dfという名前で保存します。データの名前はnameの欄を使います。
print(df)
#保存したdfを表示します。
age sex height weight
name
A 25 male 181 81
B 40 female 158 61
C 32 male 165 67
D 37 female 171 61
E 56 male 175 89
F 49 female 161 61
G 65 male 168 72
H 72 female 155 57
I 58 female 148 52
J 41 male 176 85
変数「df」に
データが読み込まれます。この形式は「データフレーム」と呼ばれます。
②seabornの場合
ここで、
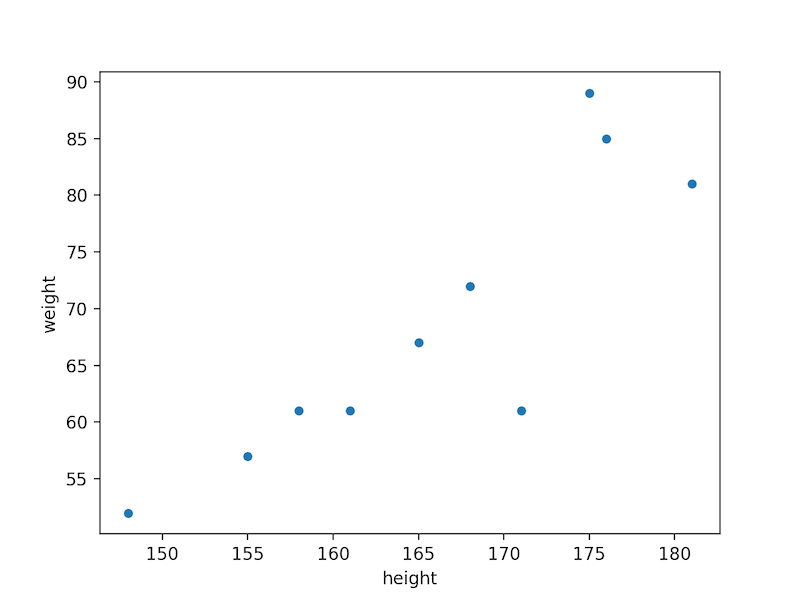
sns.scatterplot(data=df, x="height", y="weight")
#散布図を書く。 データフレームはdfを使用する。 x軸は"height" y軸は"weight"のデータを使用する。
plt.show()
#グラフを書く。
とするとグラフが描画されます。
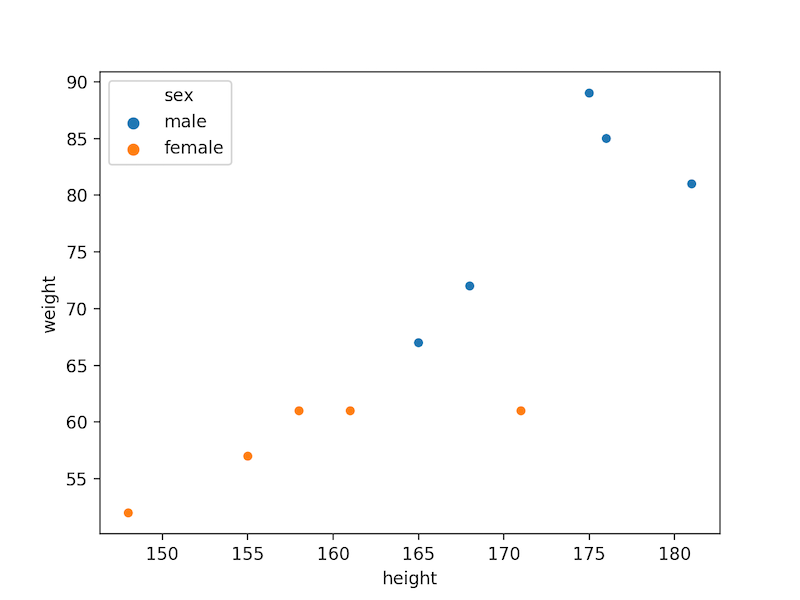
男女別に分けたいときなど、グループで分けるなら「hue」という変数で指定します。
sns.scatterplot(data=df, x="height", y="weight", hue="sex")
# "sex"(性別)でグループ分けをする
plt.show()
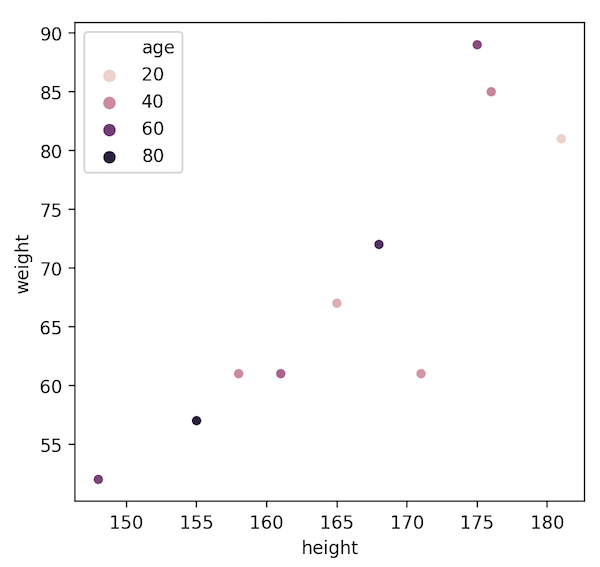
年齢別のときはグラデーションにしてくれます。
sns.scatterplot(x="height", y="weight", data=df, hue="age")
# "age"でグループ分けをする
③ matplotlibの場合
同じことをmatplotlibでもできますが、matplotlibではx,yの値を数列として入力する必要があります。
plt.scatter(x=df['height'], y=df['weight'])
#matplotlibで散布図を書く。xにはdf内の"height"の数列を入れる。yにはdf内の"weight"の数列を入れる。
plt.show()
とすると、同じグラフが得られます。
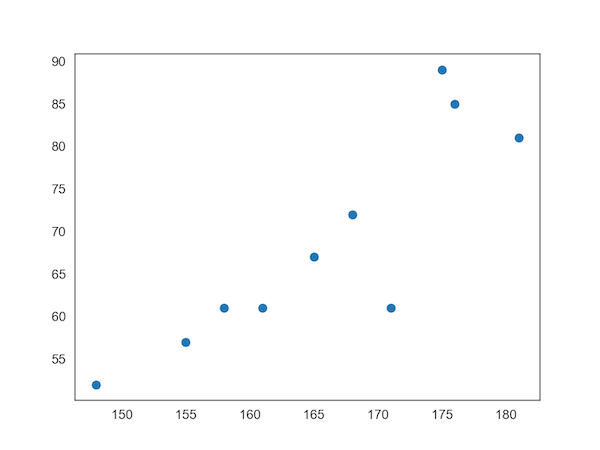
seabornの時とは違い、縦軸、横軸のラベルは設定してくれません。
自分で設定する必要があります。
ここでdf[‘height’]には読み取ったデータの中の身長が入っています。
print(df['height'])name
A 181
B 158
C 165
D 171
E 175
F 161
G 168
H 155
I 148
J 176
Name: height, dtype: int64
print(df['weight'])name
A 81
B 61
C 67
D 61
E 89
F 61
G 72
H 57
I 52
J 85
Name: weight, dtype: int64
print(type(df['height']))class ‘pandas.core.series.Series’
ここでデータ df[‘height’], df[‘weight’]はpandasのDataSeriesという形式ですが、普通に数字のリストでもいけます。
sample_height = list(df['height'])
print(sample_height)Out[30]: [181, 158, 165, 171, 175, 161, 168, 155, 148, 176]
sample_weight = list(df['weight'])
print(sample_weight)[81, 61, 67, 61, 89, 61, 72, 57, 52, 85]
それぞれのデータを単なるリストに入れます。
print(type(sample_height))class ‘list’
plt.scatter(x=sample_height, y=sample_weight)同じ結果ですね。
matplotlibで色分けするときは、色もサンプルと同じ数のリストにして代入することになります。
だから少し面倒になります。
まず性別から色のリストをつくります。
color_list = df['sex'].replace('female','red').replace('male','blue')
print(color_list)name
A blue
B red
C blue
D red
E blue
F red
G blue
H red
I red
J blue
性別に対応して男性=青、女性=赤で色分けの表ができました。
plt.scatter(x=df['height'], y=df['weight'],c=color_list)
plt.show()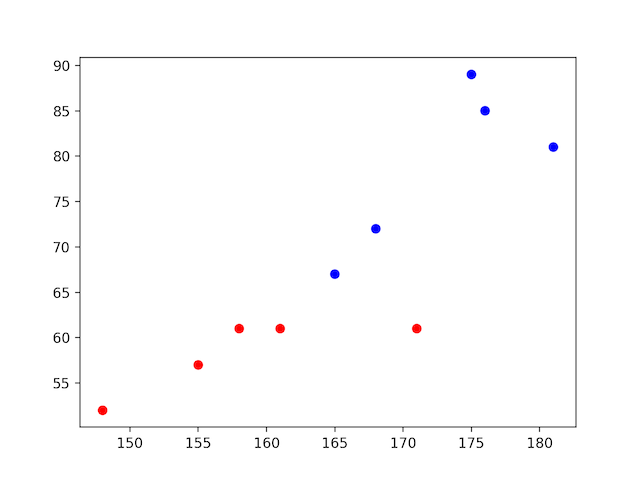
ちょっと手間がかかりますね。
ここまでのコードをまとめて書くと、
「sample_data.csv」からグラフを書く時
seabornは
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
df = pd.read_csv('sample_data.csv', index_col='name')
sns.scatterplot(data=df, x="height", y="weight")
plt.show()
matplotlibは
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('sample_data.csv', index_col='name')
plt.scatter(x=df['height'], y=df['weight'])
plt.show()色分けなど情報を加えるとなると、seabornはプロット内に情報を書けばよいのですが、matplotlibは行を増やさないといけません。
④seabornの可視化ツールの例
リストを一つ一つ設定できるという意味ではカスタマイズはできますが、
早く可視化するという意味ではseabornの方が楽です。
seabornには統計的なデータを可視化するツールがあります。
例えば
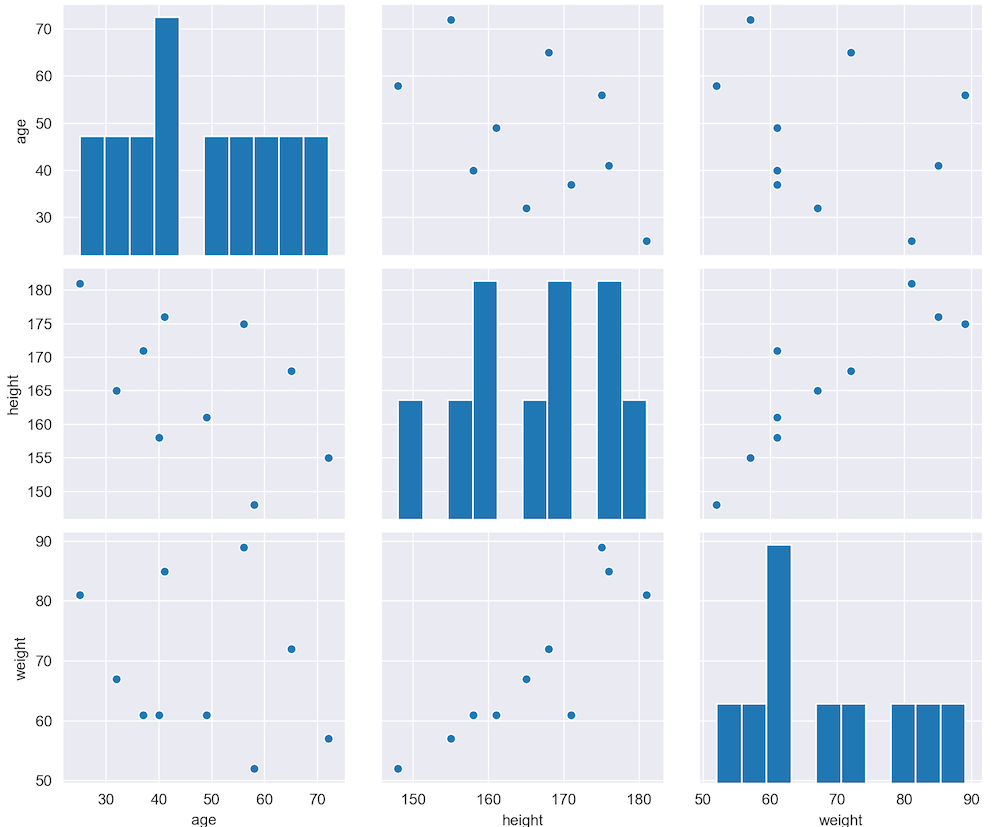
sns.pairplot(df)
plt.show()としてやると、各項目の相関関係が表にできます。
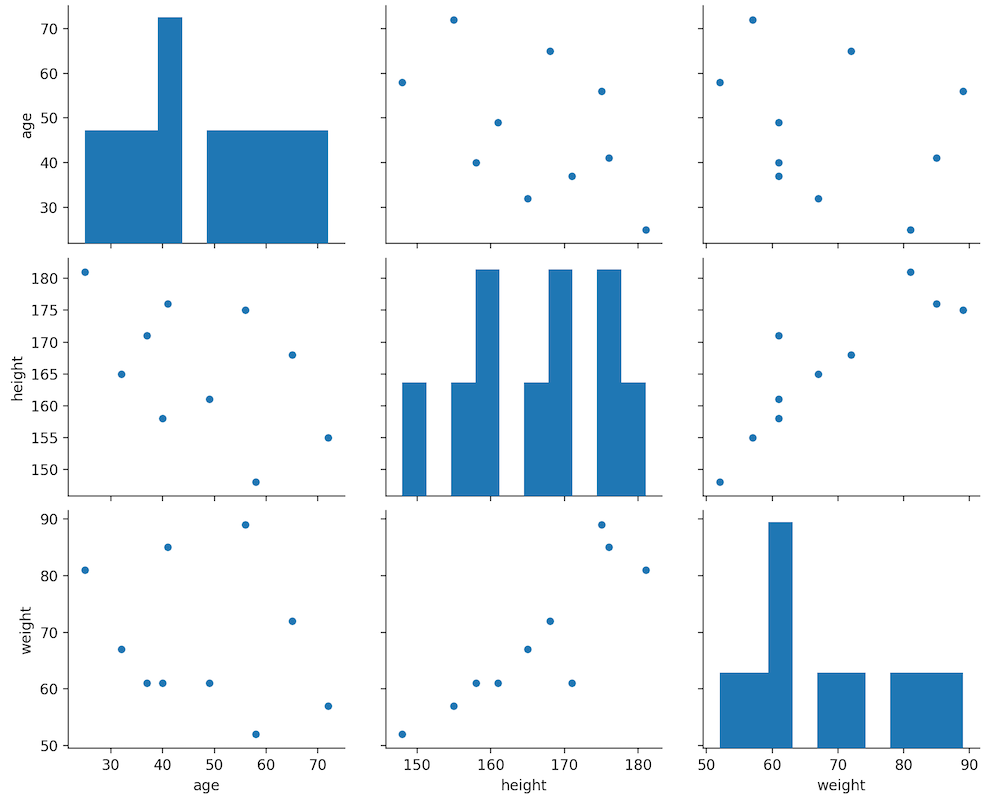
これを見ると、身長と体重の相関が強いということがひと目でわかります。
また、背景の色を変えると見やすいときにも、seabornはもともとの設定が数多く入っており、見やすいように変更できます。
例えば
sns.set_style("darkgrid")
sns.pairplot(df)
plt.show()とすると線がはっきりして値が見やすくなります。
勉強方法
公式のDocumentationを読む
これが一番大事だと思っています。
matplotlibやseabornはブログページなどにたくさん解説がのっています。
ただ、文法上さまざまなスクリプトの書き方があるため、混乱する事が多いです。
まず公式のDocumentationを読むことをおすすめします。
理由は
・それぞれのグラフに関して設定できるパラメータがすべてわかる
・公式ドキュメントの記載に慣れることができる
公式ドキュメントのページです。
例としてseabornのscatterplotのページを載せます。


はじめは英語なのでドン引きしてしまうかもしれませんが、カッコ内にx,y,hueをはじめとして使用できるパラメータが示されています。
また、各パラメータの記載もしており、それぞれに対する例Examplesも書かれています。
matplotlibでも同様のページがあります。
最近は日本語のわかりやすいページも増えており、Googleで調べると上位に日本語のページがくることが多いですが、公式ドキュメントは必ず一度は目を通しましょう。
学習教材で学ぶ
私自身データ分析を系統だって勉強したのはデータキャンプDataCampです。
データサイエンスに特化しているだけあり、学習教材としてはDataCampが最短だと思います。
ホームページ上にスクリプトを書くだけで勉強でき、グラフにする表データなども読み込む必要がありません。
DataScientistコースでは、Introductionのコースが終わるとすぐにmatplotlibの使い方をやります。
グラフを多用したい人は、表計算用のPandasの学習まで終えた時点でData Visualization with Pythonのコースをやってもいいと思います。 かなりかっこいいグラフの描き方が学習できます。
表の可視化などは教科書だと、どうしても表をうつしたり手間がかかります。
この点はオンライン学習に利がありますね。
興味のある人は、ぜひチャレンジしてグラフのクオリティアップを目指してみましょう。
↓
DataCampのデータサイエンティストコース(外部リンク)